朱雀-新一代前端分发解决方案[二]
本节内容
上一节讲了目前大多数人使用到的上线流程,以及对应几种情况的优化。同时也提出了全新的上线方式。这节就实际的讲一下该怎么实现一个我们自己的发布系统。
为了兼容目前现有的运维体系,发布操作并不做任何改动。已有的项目可以直接去掉编译之后的流程,接入新的流程。
如果可以全部重新开发,可以在现有代码的基础上增加编译的流程即可。
流程设计
整体的流程如下,分为3个阶段的实现。
上传流程
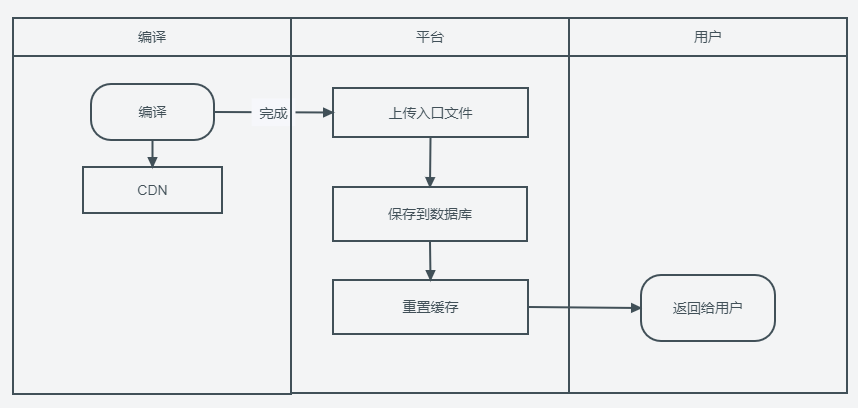
上传流程对应的是旧的流程中编译之后的阶段。主要是上传入口的index.html文件。
当前端项目编译完成之后,会产出一个或几个静态资源文件目录。我们可以将需要使用CDN的部分使用API或者CLI上传到CDN服务。
如果不需要CDN服务,可以将这部分文件上传到某个固定的NGINX服务器,由NGINX充当静态资源的下发服务。参考 nodejs实现上传功能
注意一下,多个静态资源存在互相干扰覆盖的情况。可以使用文件hash值作为文件名称的一部分。也可以根据编译日期全部隔离。好处是隔离的文件互不干扰,坏处是用户需要更新的文件变多,在项目较大的情况下会造成项目加载慢的情况。
更精细的方式是使用ServiceWorker管理静态资源,更新需要更新的部分。这块内容需要更多的服务支持,这里就不展开讲解了。
版本管理
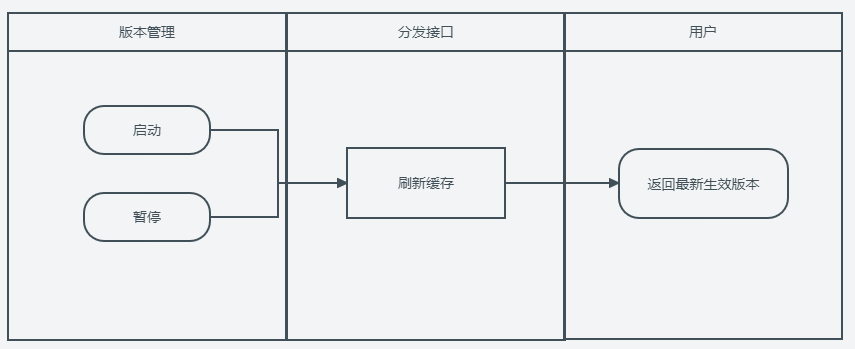
上传之后的index.html入口文件会作为一个版本来管理。主要的管理方式就是生效和失效。
根据上传的顺序,晚上传的生效版本会覆盖早上传的生效版本。在数据库设计上可以减少数据库的压力。一年几个亿的版本管理都可以非常轻松。
测试环境上传之后直接生效,生产环境上传之后需要手动确定生效。毕竟前后端的发布还是有一个时间差和生效顺序的。在完全考虑后端兼容老版本的情况,需要等待后端服务全部完成之后才能统一切换到新的版本。如果不能统一切换,也要等待后端发布完成之后再切换。
同时,这个地方也可以根据需要增加各种自定义的生效逻辑。比如:百分比的灰度、白名单、有标记的流量管理等各种逻辑。具体可以看自己的需求,再后续的设计中也会将到几种生效的实现方式。
分发流程
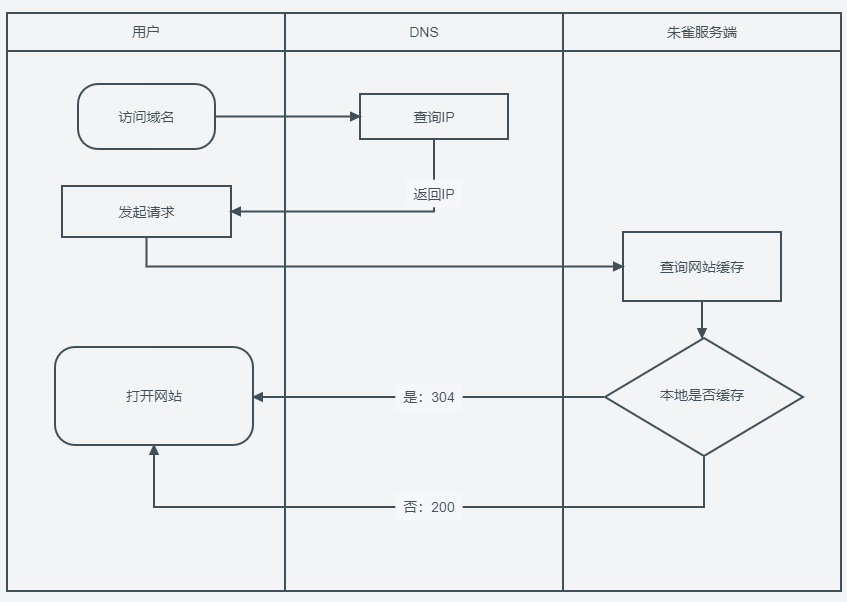
到用户侧的逻辑和版本管理是强关联的。生效和失效需要实时变更。正式版和测试版的切换也要非常及时,根据服务器间通信的时间,要保证生效的时间再200ms内。
创建server项目
大体了解我们的流程设计之后,我们还要考虑有哪些功能是我们要实现的,有核心和重点非重点的区别。我们应该优先考虑核心能力的实现,同时兼容其他能力的扩展。
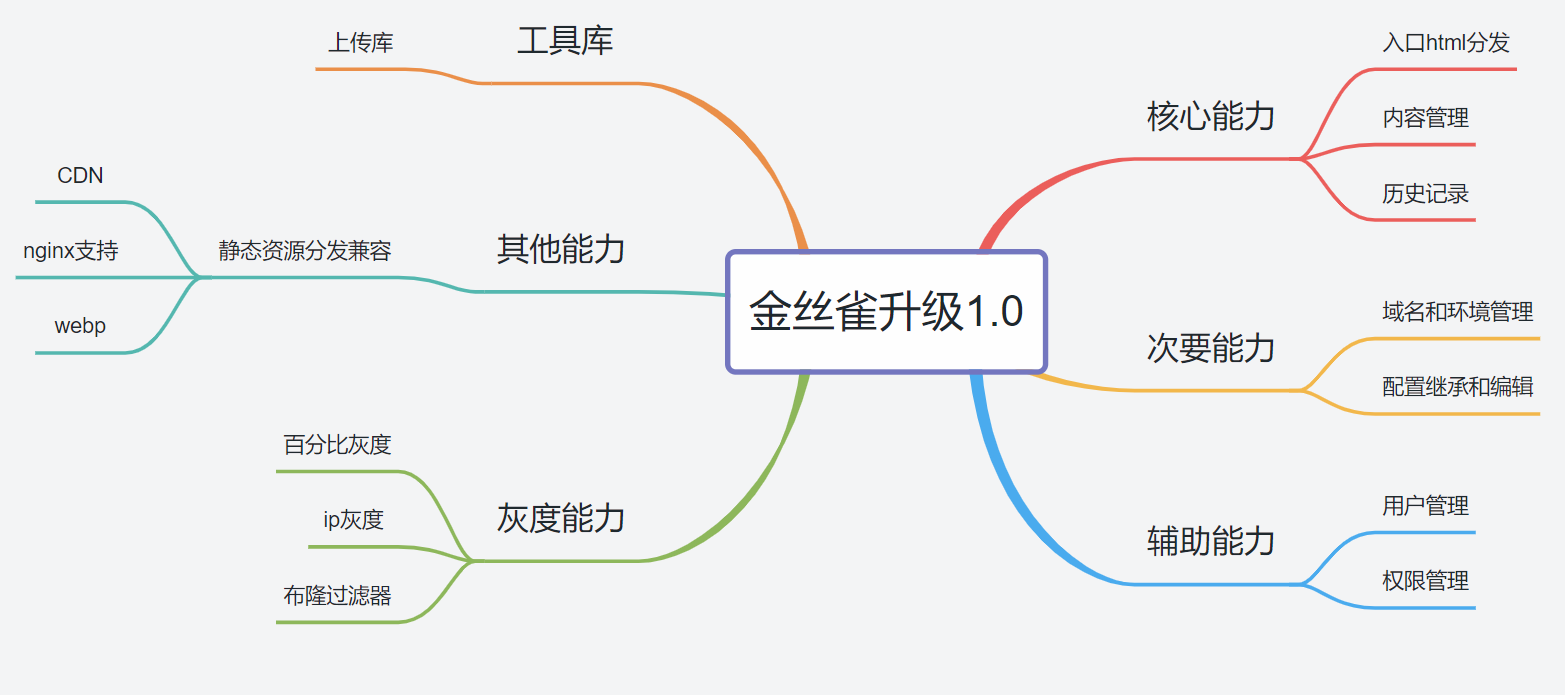
可以看到我们的项目分为几个大块:
核心能力:分发的设计。
重点能力:环境和配置管理、用户和权限。
非重点能力:上传库(直接上传也能实现)、静态资源的兼容、灰度能力。
接下来我们开始创建我们的服务端项目。这里我使用我之前的模板来直接创建。npx create-app-git init phoenix-server
需要能访问github才能下载模板。
目录设计
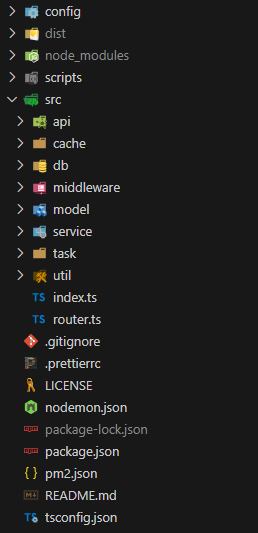
整个项目是基于约定的目录设计,这里简单介绍一下每个目录的含义和功能。
config,主要放各个环境的配置,默认使用default.js为基本配置。dist,整个项目使用typescript开发,这个文件是编译之后文件,生产可以直接使用这个目录作为最终目录。node_modules,所有依赖的三方库的存放位置。scripts,编译使用到的脚本目录,目前并无作用,可以放一些编译前后需要执行的脚本。src,源代码主目录。src/api,api目录,接口的实现源文件。src/cache,目前存放缓存相关内容,不在约定范围内。src/db,数据库连接文件,包括mysql、MQ、redis等。src/middleware,中间件目录,目前存放鉴权和跨域等中间件。src/model,实体对象存放目录,主要放数据库存储对象的约定和操作。src/service,方法实现目录,主要是各个功能的实现。src/task,定时任务目录,自启动和对外提供部分功能。src/util,工具库,全部是函数,随便使用。src/index.ts,整个项目的主入口,包括各项内容的启动和服务监听的启动。src/router.ts,路由文件,所有路由都在这里。.gitignore,git仓库的排除文件。.prettierrc,风格和规范的简单约束。LICENSE,开源协议。nodemon.json,ts的执行文件,在开发阶段常用。package.json,项目的配置文件,包括项目名称、三方库的引用等。pm2.json,守护进程的配置文件,默认使用pm2,也可以使用docker等其他方式。README.md,项目介绍文件。tsconfig.json,ts的配置文件,这里将ts文件编译成了commonjs格式。
配置管理
多个环境下是一定会遇到不同环境不同配置的问题。实现方式也是非常的多。
有的使用环境文件,比如.env.production这种,根据环境的不同加载不同的配置。
这里介绍另外一种方式,同样也是根据环境的不同加载不同的配置。区别是这里还支持多种文件格式,包括js文件。既可以写注释,同时也能写逻辑。
默认使用default.js文件,把生产的配置写好,并且增加各种注释,防止忘记。(默认文件应该是开发使用的配置,这里由于所有服务都可以在本地访问,统一使用127.0.0.1更方便,开发和生产配置一样,只有测试不一样)
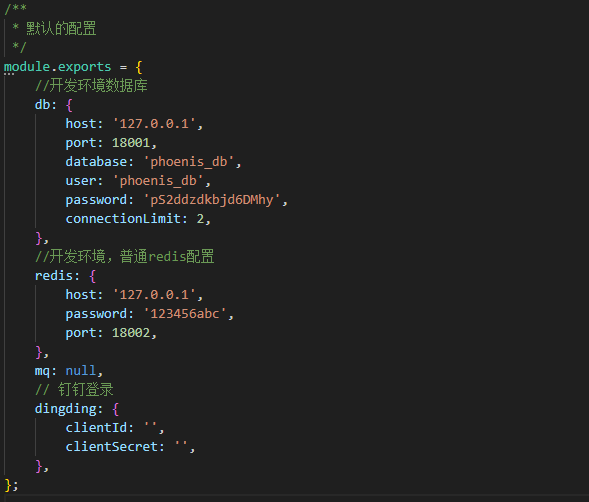
再根据不同的环境参数NODE_ENV=xxx配置同名的json格式的文件。比如测试环境NODE_ENV=test,增加test.json文件,把对应的配置修改成该环境的配置即可。
api设计
api就是我们实际要用到的入口了。这里我们把整个api分成3个部分来实现。
中间件
中间件是路由进入真正的函数前的一部分,我们需要在正式开始前做一些检查。
中间件-鉴权
所有后台的路径都是需要有鉴权才能使用的。我们来简单实现一个用户信息检查的函数。
import Router from '@koa/router';
import { CheckToken } from '../service/user';
import { BeError } from '../util/response';
export default async function AuthAdmin(ctx: Router.RouterContext, next: any) {
try {
if (!ctx.headers.token) throw new Error('未登录');
const uuid = await CheckToken(ctx.headers.token as string);
if (!uuid) throw new Error('登录已失效');
ctx.uuid = uuid;
await next();
} catch (error) {
console.log(error);
ctx.body = BeError(error.message, 401);
}
}
登录之后的用户会在head中增加用户校验参数token。我们可以判断是否有token,以及token是否是系统生成的来检查用户是否登录,登录的身份是否合适。
/**
* 检查token是否存在
* @param token token
* @returns
*/
export async function CheckToken(token: string) {
const key = USER_TOKEN_PREFIX + token;
const data = await Redis.get(key);
if (data) return data;
return null;
}用户的token存放在我们的redis中,检验的时候只需要鉴权token是否存在即可。(如果使用较多还需要增加限流,避免暴力破解)
中间件-跨域
我们的一部分接口时公开在网络上的。如果这部分接口还需要其他域名的网址访问,我们还要实现一个简单的跨域中间件。
/**
* 跨域
*/
export default async function (ctx: any, next: any) {
ctx.set('Access-Control-Allow-Origin', '*');
ctx.set('Access-Control-Allow-Headers', 'Content-Type, Content-Length, Authorization, Accept, X-Requested-With, Token');
ctx.set('Access-Control-Allow-Methods', 'PUT, POST, GET, DELETE, OPTIONS');
if (ctx.method == 'OPTIONS') {
ctx.status = 204;
ctx.body = 200;
} else {
await next();
}
}跨域的原理大家应该都知道,这里设置的是不限制任何人使用。我们正常使用的时候可以在这里增加具体的使用范围,减少被滥用的情况。
内部API
内部API指的是我们后台的api。这部分API需要鉴权中间件,同时也需要实现我们的几个功能的能力。
版本管理类。
项目管理类。
日志类。
用户权限类。
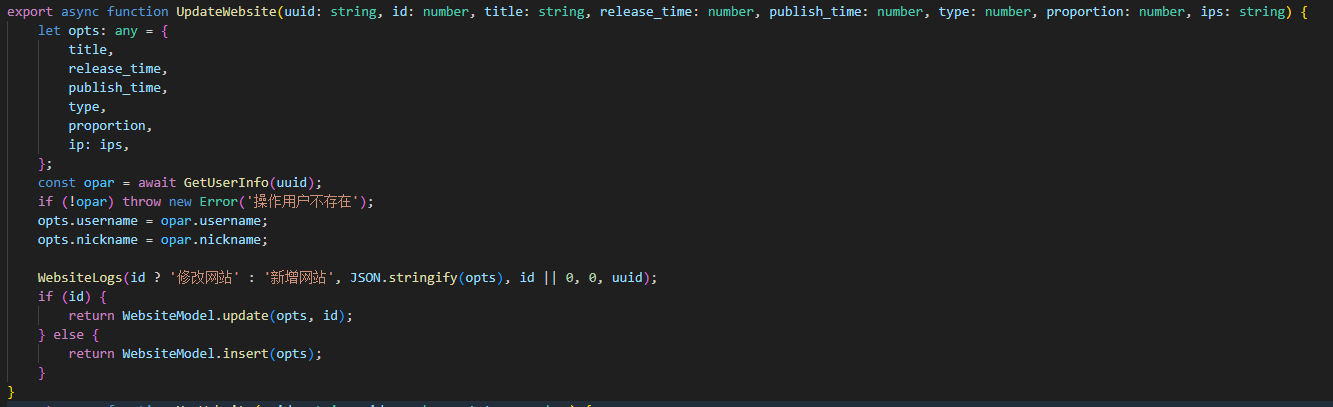
我们可以看一下简单的实现一个编辑版本信息的API。首先是路由部分的实现。
router.post('/edit', AuthAdmin, async function (ctx) {
const { id, title, release_time, publish_time, type, proportion, ips } = ctx.request.body;
try {
if (!id) throw new Error('不存在的内容');
await UpdateWebsite(ctx.uuid, id, title, release_time, publish_time, type, proportion, ips);
ctx.body = BeSuccess();
} catch (error) {
console.log(error);
ctx.body = BeError(error.message);
}
});可以看到,我们首先选择使用post方式接受参数。同时将这些参数从body中获取到。kao项目默认使用的是json格式传递。我们可以放心的使用对应的数据类型。
中间紧跟的是我们刚才实现的用户鉴权中间件,这里可以保证用户都是登录的。同时前端部分也根据固定的错误码来跳转登录页。
再往后是我们调用具体的函数,并且将内容返回。这里封装了一个简单的返回内容的函数。我们将返回的json结构固定化,同时可以使用默认的返回码来标记操作成功还是失败。
真正的功能实现我们放在service目录下。整体的功能分隔成了几个模块,我们在不同的模块实现不同的方法,每个模块负责的内容不同。这样整体的逻辑是统一的,在后面扩展和更新的时候也可以非常方便的继续开发。
外部API
除了内部使用之外,我们还需要创建几个外部使用的,包括网站的上传,网页的分发等。这里简单介绍一个分发的逻辑,其他部分可以在后面的文章中详细了解。
我们首先需要将域名解析到朱雀的服务端,保证我们的项目是入口。
app.use(home);其次在路由设计上需要增加对所有路由的拦截,这个地方类似于nginx针对前端项目的路由逻辑。在koa中比较简单,我们只需要统一拦截就可以了。
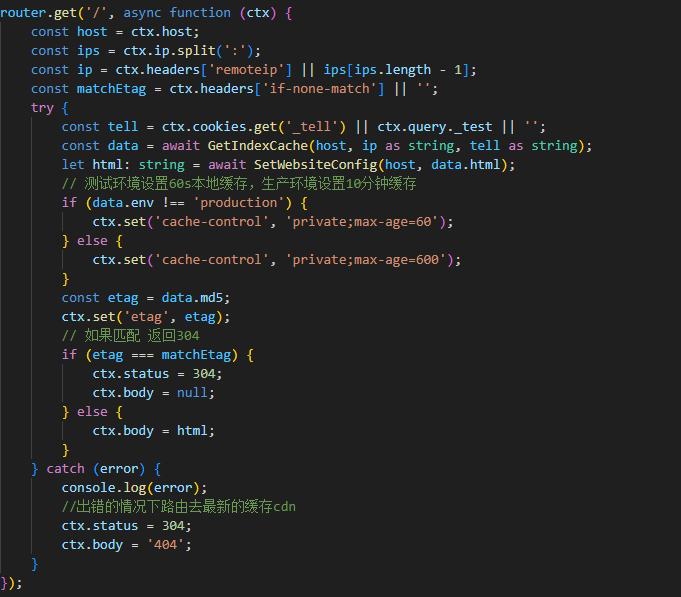
在路由中,我们需要将入口文件跟进规则进行下发。同时也可以增加缓存机制来限制请求的次数。这里我们简单的设置一个本地缓存时间和304缓存的逻辑。
创建web项目
我们再来看前端部分的实现。前端的基础模板使用的是vue-admin-template的简化版本。我们目前还不需要多复杂的设计,只需要实现核心的功能即可。
界面设计
整体界面分成几个大的模块,我们都来看一下。这里直接看最终效果,PRD部分就略过了。
面板
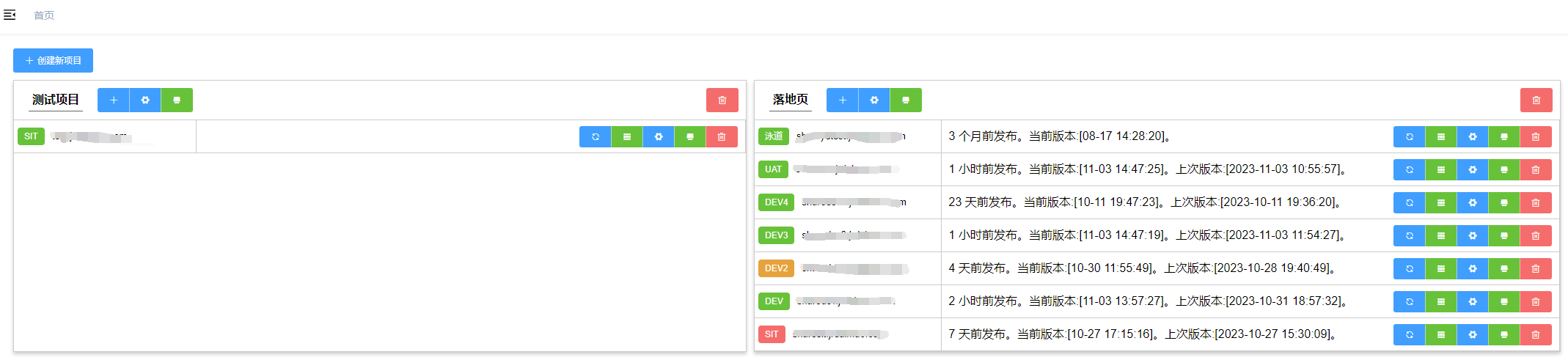
面板部分主要是为了观察最近的发布以及设置对应的项目和配置内容。
发布列表
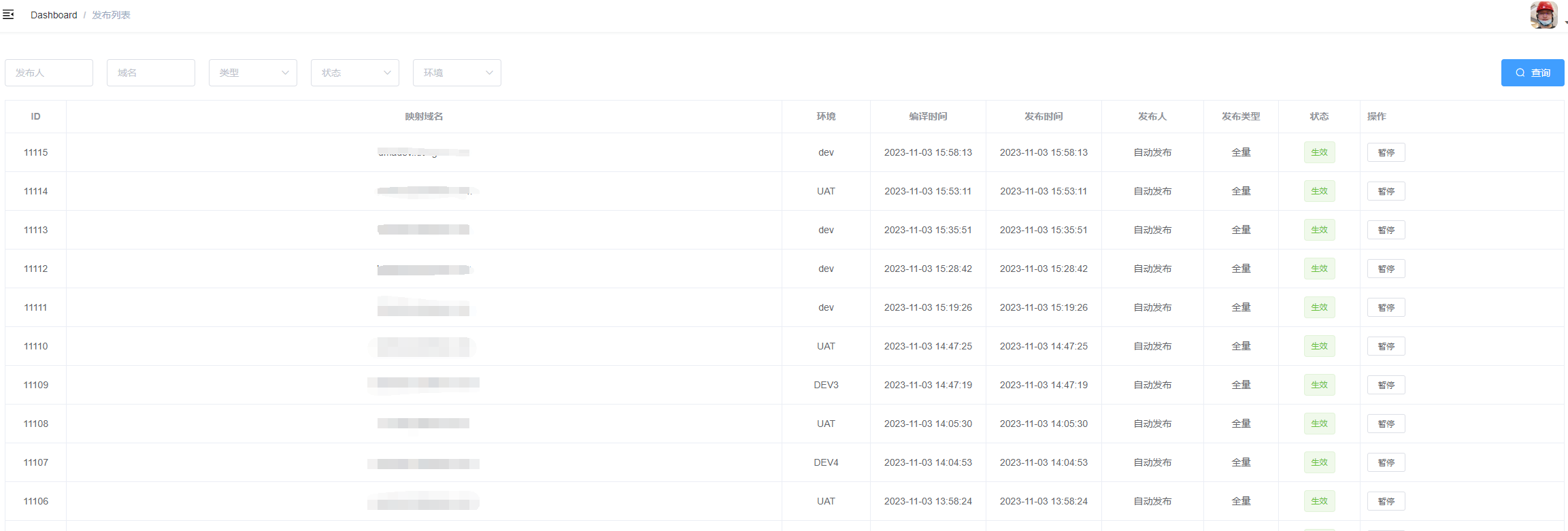
发布列表主要是展示所有的已发布的版本,同时也可以通过路由参数或者筛选项来看对应的内容。右侧的操作按钮可以用来编辑、启动、暂停、一键发布等功能。
用户管理
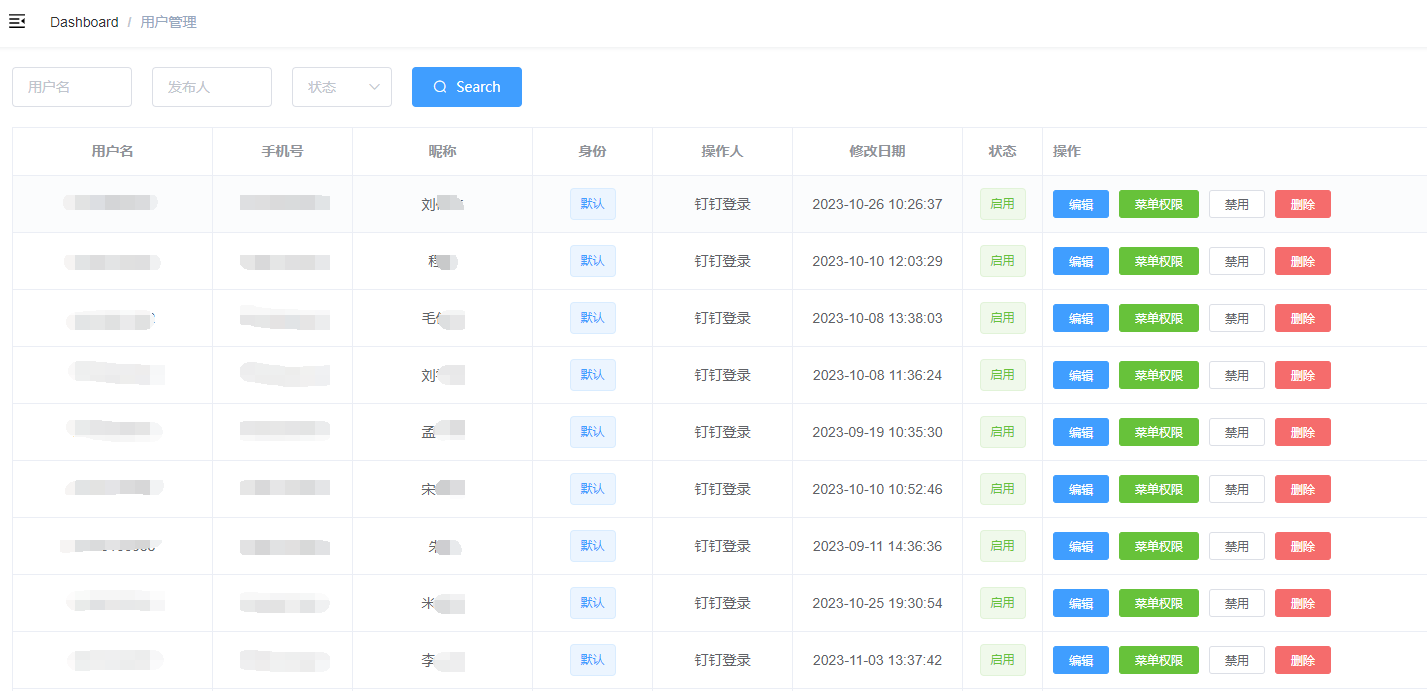
这里的用户管理我增加了一个钉钉登录,看实际需要我们可以自由增加。
日志列表
日志主要是为了记录操作,一方面是防止误操作,可以根据日志恢复,另一方面也是要看看是哪些人操作的,留个记录。
总结实现
上面几块部分我们基本实现了朱雀的核心内容,根据这些逻辑也能实现自己的发布系统。同时还有源代码的参考,在源代码的基础上进行二次开发也非常方便。
在后面的文章中,还会有更多的功能实现和精细化的功能实现的文章,也可以关注之后慢慢了解。