朱雀-前端部署的几种方式[三]
前言
在简单的研究了新型的发布流程之后,我们再集中精力研究一些涉及到的知识点。本章内容的知识点就是前端资源的部署。
我们知道前端最后编译或者不编译,用户拿到的都是静态资源。那么前端的部署其实说到底就是在可选的编译之后再增加一个分发给用户的逻辑。
部署和分发流程
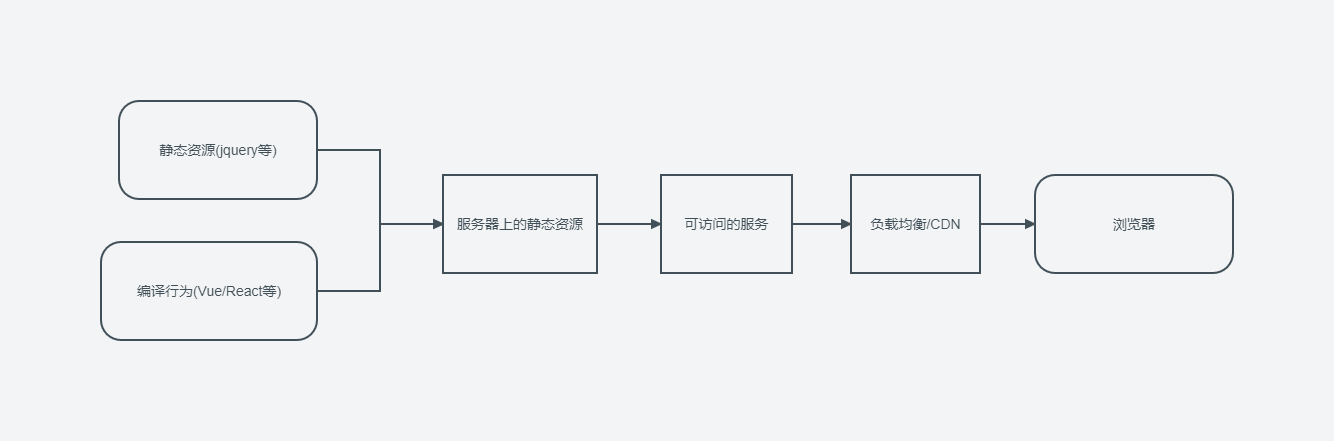
我们通过上面的简化流程可以看出来,在拿到静态资源之后,还需要把静态资源放在服务器上,才能做到分发给用户。
分发还有一个备选项是使用CDN,将一部分静态资源使用CDN的节点去分发。相比我们自建的服务,CDN有成本小,下载速度快的特点。在有能力的情况下,前端还是推荐尽量搞一个CDN的服务。可以在推送到服务器之后同步完成推送CDN的流程。
用户端基本就是浏览器。浏览器访问页面的时候第一步就会下载我们服务器上的入口文件,通常是index.html或者其他的文件(常见于MPA模式,SPA模式只有一个入口文件)。
而在用户下载文件的过程中其实还要经过各种中间商的节点。比如小区运营商、城市级的电信运营商等等。他们的服务一般也会有缓存,常见的情况是在不适用SSL的时候,页面被注入广告。或者是运营商有域名的缓存,在切换解析的过程中更新非常慢。以及使用CDN之后CDN的节点不够给力,直接击穿或者CDN文件生效过慢,导致访问404,节点缓存了404的结果。这些问题都是在这个流程中需要注意的问题。
除了上面的全量更新的逻辑之外还存在一个增量更新的情况。比如部分静态资源更新或者离线情况下的增量更新。这些一方面需要考虑版本以及跟更新时机的问题,另外一方面也需要考虑更新逻辑或者是最小更新文件的问题。
发布到服务器
前端的部署有非常多的方式,我们先挨个看把文件发到服务器的方式。这里默认是编译之后的内容,不考虑编译的过程了。
SSH/远程桌面等
这种方式主要是在蛮荒时期,或者是初期没有任何手段着急上线的时候。静态文件要想发布到服务器上,只能通过类似于SSH或者是打开远程桌面然后复制粘贴的方式。
scp /path/filename username@servername:/path/这种方式最大的问题是要手动操作,在操作过程中没有任何保证。优化方式(一般是出问题之后才考虑):在复制之前先打包,然后在服务器上解压缩。这种方式还是人工操作,但是已经没有了人操操作可能出现的失误情况。
# 压缩
tar -zcvf test.tar.gz ./test/
# 解压缩
tar -xzvf test.tar.gz新的问题是,在覆盖旧文件之后旧文件已经不存在了。如果用户在访问的过程中需要这些文件,则浏览器端白屏报错等情况就不可避免。优化方式:使用版本号来隔离新老文件。比如使用发布的日期来隔离,新老文件同时生效。麻烦的地方是每次编译都要修图对应的文件名。而且老文件长期占地方,需要定时删除。
FTP等
这种方式常见于开始做基建的远古时期。有一些人会使用FTP这种可视化操作来完成上面的操作。除了FTP之外还有其他的类似宝塔、独立开发的文件上传系统等。
这些工具的出现只是方便了上传的过程,减少了开发对服务器的访问范围,一定程度上保证了服务器的安全。但是在实际的使用上和SSH的方式并没有太大的区别。
有的团队会在这个基础上再做一些自己的开发,增加各种自动化的脚本。大多倾向于使用python(大多数是运维团队开发)、nodejs(前端团队开发)等来完成自动化操作,减少人工操作可能存在的问题。
一键复制粘贴
这里的一键复制粘贴主要是指脚本的开发。在上面的流程或者后面的其他种类的流程中,或多或少都会出现。这里简单使用nodejs来举例。
为了应对版本化的问题,在编译过程中会在静态资源前缀上增加版本号。最简单的版本号规则是当前时间(不建议使用时间戳,看着不方便)。
比如在react中,需要修改以下内容:
// 在config/paths.js中修改返回
const MypublicPath = "/202311081623";
publicUrlOrPath: MypublicPath,
// 如果为了方便,也可以把编译目录也修改
appBuild:"dist"+MypublicPath
另外一种常用脚本就是文件同步脚本了。比如使用FTP上传的可以参考https://www.npmjs.com/package/ftp这个库,在编译完成之后同步上传到特定目录。或者也可以使用rsync库来完成文件同步。
rsync -av root@192.168.1.77:/etc/hosts /dir1/ 除此之外的同步手段就更多了,可以使用类似云盘同步的方式,很多三方的工具都可以做到。
镜像
现在使用k8s来完成服务器管理的公司越来越多了。毕竟管理起来方便,对技术的要求比较小。那么使用镜像来同步文件变成了一个更简单的方式。
这里的同步其实已经包括到了服务的部分了。我们在编译完成之后直接使用打镜像的命令或者三方的自动打镜像+同步的命令即可。
// 使用默认的镜像配置文件打包,版本号使用当前时间
docker build -t xxxx:202311081634 .
// 推送镜像到远程仓库,一般使用云服务器,推荐使用三方来自动化处理
docker push xx.xx.xx.xx:5000/xxxxx上面的操作最好使用三方比如Jenkins这种来操作,比较方便。
我们再看一下镜像配置文件的内容:
FROM nginx:1.17.5-alpine
ENV RUN_GROUP nginx
ENV DATA_DIR /home/www/dist
# 复制源码到容器的/home目录
COPY ./dist /home/www/dist
COPY ./docker/nginx/conf.d /etc/nginx/conf.d
# 指定执行的工作目录
WORKDIR /home/www
EXPOSE 8082
#CMD 运行以下命令
CMD ["nginx", "-g", "daemon off;"]我们直接使用NGINX的镜像,同步把文件复制到对应的目录中,然后启动NGINX服务即可。整个镜像除静态资源之外大概3MB左右。
使用三方:Jenkins
三方的存在大部分是通过三方已经开发好的流程来完成自动化操作。比如目前很常用的Jenkins,可以通过配置插件来自动完成镜像打包或者文件同步的操作。当然上面的版本号还不支持,需要开发者在代码中增加这部分的开发工作。
发布到CDN
除了上面的正常操作之外,还有一个分支选项----增加CDN,这里非常推荐。
CDN的服务器是一个根节点再加树形的多节点组成的分布式服务。一些使用边缘节点的更是非常的便宜。我们利用CDN可以在一定程度上增加前端项目的加载速度。
在使用之前还需要注意,CDN的同步是需要时间的,所以需要确定CDN上有项目文件之后再切换到新版本是非常重要的。
CDN的使用也可以分成两种方式:
分发文件到CDN。一般CDN厂商都提供上传文件的API,可以直接使用这种API来上传文件。再文件上传完成之后再切换新版本。
使用回源服务。在用户访问CDN的时候,如果是首次访问并且不存在的文件,CDN回去回源地址的同一个目录下查找文件。文件存在返回文件,文件不存在缓存404。这个相对来说比较简单,但是要小心别提前切换版本,否则CDN会缓存一堆404。
回源地址其实也是一个NGINX或者类似的服务。正常来说,测试环境使用服务器提供静态资源访问服务,线上提供CDN服务是性价比非常高的。这样在前端不做大的修改的情况下就能兼容。
如果使用云服务器还可以把回源服务和编译服务挂上同一个云盘,这样编译之后的文件只需要执行cp命令就行,远比增加一个上传脚本来的实在。
服务器,启动!
在静态资源就位之后,我们就要启动我们的服务了。这个服务主要的职责是对外提供静态资源的下发能力。
类似的服务非常多,我们的选择也非常多。这里简单列举2个例子。
NGINX
NGINX可以说是仅几十年使用最多的服务了。基于它的魔改更是数不胜数。它体积下,并发高,处理能力强大,还支持扩展lua、php、video等各种能力。我们要使用它首先是需要在服务上安装它。
参考我之前写的文章或者镜像。Github
#!/bin/bash
#variables
nginx_pkg="nginx-1.17.5.tar.gz"
nginx_rel="nginx-1.17.5"
nginx_install_doc=/usr/local/nginx
nginx_start_doc=$nginx_install_doc/sbin/nginx
nginx_user="www"
nginx_group="www"
check() {
#检测wget
if [ ! -x /usr/bin/wget ]; then
yum install -y wget >/dev/null
fi
}
install_pkg() {
#安装依赖
if !(yum install -y gcc gcc-c++ pcre-devel zlib-delvel openssl openssl-devel 1>/dev/null); then
echo "ERROR:yum install error"
exit 1
fi
#下载源码包
if (wget -O /usr/local/src/$nginx_pkg https://nginx.org/download/$nginx_pkg 1>/dev/null); then
mkdir $nginx_install_doc
tar -xf /usr/local/src/$nginx_pkg -C /usr/local/src/
if [ ! -d /usr/local/src/$nginx_rel ]; then
echo "ERROR:not found $nginx_rel"
exit 1
fi
else
echo "ERROR:wget file fail"
exit 1
fi
}
nginx_install() {
#创建用户
useradd -r -s /sbin/nologin www
#编译安装
cd /usr/local/src/$nginx_rel
if ./configure --prefix=$nginx_install_doc --with-http_ssl_module --with-http_stub_status_module --with-http_realip_module --user=$nginx_user --group=$nginx_group 1>/dev/null; then
if make 1>/dev/null; then
if make install 1>/dev/null; then
echo "make install successful"
else
echo "make install fail"
exit 1
fi
else
echo "make fail"
exit 1
fi
else
echo "./configure fail"
exit 1
fi
}
#启动,测试
nginx_start() {
if $nginx_start_doc; then
echo "nginx start SUCCESS!"
curl http://localhost:80
else
echo "nginx start FAIL"
fi
}
check
install_pkg
nginx_install
nginx_start利用上面的脚本安装NGINX或者使用镜像之后,我们就需要配置对应的配置文件了。需要注意的是MPA只需要配置根目录就好了,SPA的还需要增加对文件的适应。正常路由对应的是具体的文件,但是在SPA模式下始终都是index.html文件。
server {
listen 8082;
root /home/dist;
location /static {
charset utf-8;
root /home/dist;
}
location / {
charset utf-8;
root /home/dist;
index index.html index.html;
# 尝试将所有页面都对应到唯一的入口文件
try_files $uri /index.html;
}
}上面的配置中同步还完成了对静态文件的代理,其他的API的代理可以参考NGINX的教程来完成配置。
NodeJS
除了上面的方式之外,我们还可以自己完成静态资源的服务。一般情况下我们都是需要在静态资源的基础上做一些特殊操作才需要这么干。正常情况下请相信NGINX远比我们写的更厉害。
比如我们使用KoaJS来做静态资源的代理。简单的使用方式如下:
const Koa = require("koa");
const router = require("koa-router")();
const static = require("koa-static");
const app = new Koa();
//如果在static 里面找不到 就会去public 里面去找
app.use(static(__dirname + "static"));
app.use(static(__dirname + "public"));
app.use(router.routes());
app.use(router.allowedMethods());
app.listen(8080, () => {
console.log("服务启动成功");
});这里再增加一个自动转化图片格式为webp的例子。众所周知,图片一直是占用资源的大头,那么性能更好,体积更小的webp格式就非常有必要使用了。这里的逻辑非常简单,如果文件不存在就自动化成webp。
我们首先需要修改NGINX的配置文件,增加不存在的时候使用我们的NodeJS服务。
location / {
root /static/prod/;
index index.html index.htm;
try_files $uri $uri/ @backend;
}
location @backend {
proxy_pass http://127.0.0.1:8080;
proxy_set_header Host $host;
}通过NGINX来分担大部分流量,然后在文件需要转化的时候,我们在自己处理图片格式。(也可以一把梭,都自己处理了算了。反正也是使用CDN,不考虑大并发了。)
const Koa = require('koa');
const { koaBody } = require('koa-body');
const { cpus } = require('os');
const { ImagePool } = require('@squoosh/lib');
const fs = require('fs');
const path = require('path');
const mime = require('mime');
//加载路由
app.use(async function (ctx) {
// 请求的文件路径
const filepath = ctx.URL.pathname.toLocaleLowerCase();
// 请求的文件后缀
const ext = path.extname(filepath).toLocaleLowerCase();
const webppath = path.join(ROOT_PATH + filepath);
const isat = fs.existsSync(webppath);
// 已经存在就返回
if (isat) {
ctx.set('content-type', mime.getType(filepath));
ctx.body = fs.createReadStream(path.join(ROOT_PATH, filepath));
return;
}
// 不存在就查找源文件
const filepath2 = filepath.replace(ext, '');
const ext2 = path.extname(filepath2).toLocaleLowerCase();
// 无后缀,找不到
if (!ext2) return (ctx.status = 404);
const isat2 = fs.existsSync(ROOT_PATH + filepath2);
// 源文件不存在
if (!isat2) return (ctx.status = 404);
// 转换源文件
const imagePool = new ImagePool(cpus().length);
const arrbuffer = fs.readFileSync(path.join(ROOT_PATH, filepath2));
const image = imagePool.ingestImage(arrbuffer);
const encodeOptions = {
webp: {},
};
await image.encode(encodeOptions);
const imgResult = image.encodedWith.webp;
await imagePool.close();
ctx.set('content-type', 'image/webp');
fs.writeFileSync(webppath, imgResult.binary);
ctx.body = Buffer.from(imgResult.binary);
});通过我们使用图片格式转换的库,一个简单的自适应的支持webp格式图片的服务端就写好了。只需要在前端代码中增加对webp的兼容就可以直接使用了。
参考文章