如何开发一个爬虫系统
NodeJS爬虫原理和实战
声明:此项目只为学习目的而开发
假如你的公司需要爬虫来给大模型填充数据?假如的你需要用爬虫来给图表提供数据支持?假如你想监控网页上最新的消息?那么写一个爬虫就是非常必要的!
爬虫能做什么
有些人感觉爬虫很难,或者爬虫离自己很远。其实爬虫不过是把人力要完成的工作变成了自动化的工作。我们从互联网上抓取信息代替的是我们需要肉眼搜索和人力操作复制粘贴的内容。
现在使用非常多的RPA工具其实就是很通用一种爬虫,它把工具界面化了,可以很具象的看到和操作要抓取的内容。但是这个工具很多时候是为了给入门的人使用的,但凡懂一些技术的人还是更希望能使用更灵活的能力来完成工作。
我们一般使用爬虫的场景有以下几个方面:
数据收集:爬虫可以收集网页上的信息,如文本、图片、视频等。这个功能的使用需要注意遵循国内法律的规定。
网页索引:搜索引擎使用爬虫来索引网页,以便用户能够搜索到相关内容。大部分搜索引擎都会使用这个模式来创建对网上内容的索引。
价格比较:爬虫可以抓取不同网站上的商品价格,帮助用户比较价格。早些时候的比价网这种就是依赖爬虫来完成的。
市场研究:通过分析爬取的数据,可以进行市场趋势分析、竞争对手分析等。这个目前应该是一个很常用的场景了。尤其在大模型这么火的情况下,通过爬虫获取数据再用于大模型的再创作是非常的方便的。
社交媒体监控:爬虫可以监控社交媒体平台上的讨论,用于品牌监控或舆论分析。舆情分析在部分大公司内是非常重要的一环,也是一个很重要的使用场景。
新闻聚合:爬虫可以从多个新闻源抓取新闻,创建个性化的新闻摘要。前几年还有几个产品依赖这种模式来做产品,现在应该很少了。
自动化测试:爬虫可以用于网站测试,检查链接是否有效,页面是否正确加载等。很多项目中可以使用这个模式来完成对线上业务的自动检测。尤其是前端项目,很多时候QA团队支持不到,需要补充一些自动化手段来监控线上业务。
内容监控:爬虫可以监控网站内容的更新,确保信息的及时性和准确性。一些数据通常会在部分网站发布,可以使用这个方式来自动抓取最新的信息。
不管是工作还是个人需要,我们总要学一些爬虫相关的技术。这篇文章希望从入门到上手带着大家完成基础的开发工作。更多的内容可以看后面的爬虫系列,将完整的开发一个爬虫项目。
有哪些开源方案可以选择
大多数项目优先支持的是javascript,其次是python,再其次是其他。很多比较老的项目优先支持的是python,或者是支持大多数的开发语言。下面介绍几种使用人数较多的开源项目。
Puppeteer
https://pptr.dev/Puppeteer是一个JavaScript库,它提供了一个高级API来通过开发工具协议或WebDriver双向控制Chrome。Puppeteer默认在无头(无可见 UI)浏览器中运行,但可以配置为在可见("有头")浏览器中运行。
Puppeteer的使用人数应该是无头浏览器里面最多的了,目前在github上有88.1k的start。开发语言只支持javascript。作为一个js使用较多的开发者来说,Puppeteer是一个非常好的选择。
优势:
跨平台:
Puppeteer可以在多种操作系统上运行,包括Windows、macOS和Linux。无头模式:可以在无头浏览器中运行,这意味着不需要打开一个完整的浏览器界面,节省资源。
API 丰富:提供了丰富的 API,可以模拟用户行为,如点击、滚动、输入文本等。
支持最新
Web特性:由于基于Chrome或Chromium,Puppeteer支持最新的Web特性和标准。模拟多种设备:可以模拟不同的设备和视口尺寸,方便进行响应式设计测试。
支持多页面操作:可以同时控制多个浏览器标签页。
劣势:
只支持Chrome浏览器。
项目很安全,一些需要绕过安全的方式没有办法实现。
简单的例子:
import puppeteer from 'puppeteer';
(async () => {
// 启动浏览器并打开一个新页面
const browser = await puppeteer.launch();
const page = await browser.newPage();
// 跳转到对应的地址
await page.goto('https://developer.chrome.com/');
// 设置窗体大小,爬虫一般不需要
await page.setViewport({width: 1080, height: 1024});
// 输入内容
await page.type('.devsite-search-field', 'automate beyond recorder');
// 等待内容出现
const searchResultSelector = '.devsite-result-item-link';
await page.waitForSelector(searchResultSelector);
await page.click(searchResultSelector);
await browser.close();
})();安装使用puppeteer的要求:
Node 18+. Puppeteer follows the latest maintenance LTS version of Node
TypeScript 4.7.4+ (If used with TypeScript)
Selenium
Selenium也是一个非常流行的项目。项目不仅支持非常多的语言,如Java、C#、Python、Ruby 等。此外功能上也非常丰富,可以操作浏览器的很多API。
优势:
跨浏览器支持:Selenium 可以模拟在多种浏览器上的操作,包括 Chrome、Firefox、Safari、Edge 等。
跨平台支持:Selenium 可以在不同的操作系统上运行,如 Windows、Linux、macOS 等。
丰富的 API:Selenium 提供了丰富的 API,可以进行复杂的用户交互模拟。
集成测试框架:Selenium 可以与多种测试框架集成,如 JUnit、TestNG、pytest 等。
支持多种编程语言:Selenium 支持多种编程语言,使得开发者可以使用自己熟悉的语言进行自动化测试。
生成测试报告:Selenium 可以生成详细的测试报告,方便测试结果的分析和问题追踪。
劣势:
依赖浏览器驱动:Selenium 需要浏览器驱动(如 ChromeDriver、GeckoDriver)来控制浏览器,这增加了配置的复杂性。
浏览器兼容性问题:不同浏览器的实现可能存在差异,这可能导致在某些浏览器上测试通过,而在其他浏览器上失败。
并发执行限制:Selenium 在并发执行大量测试时可能会遇到性能瓶颈,尤其是在资源有限的环境中。
简单的例子:
const {Builder, Browser} = require('selenium-webdriver');
(async function helloSelenium() {
let driver = await new Builder().forBrowser(Browser.CHROME).build();
await driver.get('https://selenium.dev');
await driver.quit();
})();playwright
Playwright 是一个用于自动化 Chromium、Firefox 和 WebKit 的库,它允许开发者和测试人员编写脚本来模拟用户与浏览器的交互。Playwright 旨在提供一种简单、强大且一致的方式来自动化现代 Web 应用程序。
Playwright同上一个Selenium一样,本身是从测试的角度来提供支持的一个开源项目。支持Chromium、Firefox 和 WebKit协议的浏览器。功能很丰富,支持的能力非常多样化,开发语言目前支持NodeJS、Java、Python、C#。
优势:
跨浏览器支持:Playwright 支持所有主流浏览器,包括 Chromium、Firefox 和 WebKit。
跨平台支持:可以在 Windows、Linux 和 macOS 上运行。
支持多设备和视口:可以模拟多种设备和视口尺寸,方便进行响应式设计测试。
支持 WebSocket 和 Service Workers:Playwright 支持 WebSocket 和 Service Workers,可以测试复杂的 Web 应用。
支持视频录制:在测试过程中,可以录制视频,方便问题追踪和分析。
支持多语言:Playwright 支持 JavaScript、TypeScript、Python、C# 等多种编程语言。
劣势:
安装和配置:Playwright 需要安装和配置浏览器实例,这可能增加了项目的复杂性。
简单的例子:
// 启动浏览器
const browser = await chromium.launch();
// 打开页面
const page = await browser.newPage();
// 跳转页面地址
await page.goto('https://www.xiaohongshu.com/explore/66c4a0db000000001f03869b');
const title = await page.title();
await browser.close();playwright的要求
Node.js 18+
Windows 10+、Windows Server 2016+ 或适用于 Linux 的 Windows 子系统 (WSL)。
macOS 13 Ventura 或 macOS 14 Sonoma。
Debian 11、Debian 12、Ubuntu 20.04 或 Ubuntu 22.04、Ubuntu 24.04,基于 x86-64 和 arm64 架构。
chromedp
https://github.com/chromedp/chromedp
chromedp是golang开发的,适合需要golang来做自动化的场景。这里只列出来,不做更多说明(没有用过不发布意见)。
简单的例子:
ctx, cancel := chromedp.NewContext(context.Background())
defer cancel()
chromedp.Run(ctx, chromedp.ActionFunc(func(ctx context.Context) error {
_, err := domain.SomeAction().Do(ctx)
return err
}))headless-chrome-crawler
https://github.com/yujiosaka/headless-chrome-crawler
headless-chrome-crawler跟上面几个相比,它的优势在于支持分布式的自动化运行。
简单的例子:
const HCCrawler = require('headless-chrome-crawler');
(async () => {
const crawler = await HCCrawler.launch({
// 执行调用的方法
evaluatePage: (() => ({
title: $('title').text(),
})),
// 结果调用的方法
onSuccess: (result => {
console.log(result);
}),
});
// 请求地址
await crawler.queue('https://example.com/');
// 请求多个地址
await crawler.queue(['https://example.net/', 'https://example.org/']);
await crawler.onIdle();
await crawler.close();
})();主流使用方式和例子
从这里开始,我们进入正式的开发过程,下面会根据现有的情况介绍一些常见的爬虫使用方式。这里使用playwright的原因是它可以绕过一些安全机制,比较方便做爬虫类的项目。还有一个比较方便的特点是它可以自定义浏览器用户目录,可以自动分开不同的登录用户。
开发环境:
node: 22.6.0。playwright:1.46.1。window:Windows 11 专业版。Chromium:128.0.6613.18。
直接解析
最简单快速的方式,其实也是最古老的方式,就是使用模拟请求的方式直接获取HTML代码。然后在用解析库(甚至直接正则匹配)查找对应的元素和内容。
这里我们推荐使用cheerio。这个开源项目提供了非常丰富的解析方法,使用上类似于JQuery的方式。对于网站反爬虫做的很一般的项目,可以使用cheerio来完成简单的网页内容抓取。
贝壳抓取的例子:
// 贝壳的反爬虫就是简单的判断header中的参数
// 页面结构也是非常简单明了,可以直接解析获取
const $ = await cheerio.fromURL('https://bj.ke.com/xiaoqu/1111027376106/?fb_expo_id=882963435674722304', {
requestOptions: {
headers: {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36',
},
},
});
const price = $('.xiaoquUnitPrice').text();
console.log(price);有些网站确实做的很差,没有任何反制措施。但是我们在实际的爬取过程中还是要尽量控制节奏,不要太快的请求和解析内容。一方面是容易造成对方网站崩溃,另一方面云服务厂商大多数有基础的防DDOS机制,可能直接就进入了黑名单。
模拟访问:dom操作
有些网站的内容获取比较麻烦,比如目前很多网站已经在使用React、Vue这种框架了。这种框架编译出来的网页是异步加载的。在第一次访问的时候只能获取到一个空壳页面和对应的js地址,还要再等待js加载完成才能看到页面内容。这个时候我们就需要一个能完成上面的渲染过程的库了。
很古老的时候,有人就开始使用是异步解析的方式获取内容了。先用一个浏览器打开对应的页面,然后再把页面渲染之后的HTML获取下来,再用上面的cheerio来完成后续的操作。有些公司甚至用这个流程来完成网页的异步渲染和HTTP缓存。
我们推荐的使用方式是:使用playwright这种开源项目,在一个代码里完成打开浏览器并等待渲染结果,然后再通过异步的方式获取到对应的DOM节点和内容。这种方式可以比较低成本的绕过大多数反爬机制,完成对内容的爬取。
// 根目录
const ROOT_PATH = process.cwd();
// 等待函数
const sleep = (ms) => new Promise((resolve) => setTimeout(resolve, ms));
const browser = await chromium.launchPersistentContext(path.join(ROOT_PATH, '.userdata/xhs'), {
headless: false,
viewport: { width: 1920, height: 1080 },
userAgent: 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36',
});
// 打开页面
const page = await browser.newPage();
await page.goto('https://www.xiaohongshu.com/explore');
// 简单使用,就硬等就行
await sleep(2000);
await page.goto('https://www.xiaohongshu.com/explore/66d585f4000000001d03a206');
await sleep(2000);
// js对象有数据
const info = await page.evaluate(() => {
function getNumber(str) {
str = str.replace('点赞', '').replace('收藏', '').replace('评论', '');
if (!str) return 0;
if (str.includes('万')) return Number(str.replace('万', '')) * 10000;
return Number(str);
}
// zan
const zan = document.querySelector('.engage-bar-container .like-wrapper .count').innerText;
//收藏
const cang = document.querySelector('#note-page-collect-board-guide span').innerText;
//评论
const comment = document.querySelector('.engage-bar-container .chat-wrapper span').innerText;
return { zan: getNumber(zan), cang: getNumber(cang), comment: getNumber(comment) };
});有些网页会对内容加密,看到的内容是正常的,但是获取的内容是一串乱码。
模拟访问:获取js对象
有些网站又不太一样,他们会把数据放在页面的一个JS对象中。比较典型的就是NextJS这种SSR项目。优势就是网站会打开更快,而且开发使用的是React等框架,开发的门槛并没有增加多少。
对于这种项目,我们可以在模拟浏览器渲染的基础上直接获取到我们要的数据(如果有合适的库,直接请求并解析JS对象也是可以的)。
在上面的代码中,我们简单修改一下就可以了。
// js对象有数据
const info = await page.evaluate(() => {
const obj = window.__INITIAL_STATE__.note.noteDetailMap[window.__INITIAL_STATE__.note.firstNoteId.value].note.interactInfo;
// zan
const zan = obj.likedCount;
//收藏
const cang = obj.collectedCount;
//评论
const comment = obj.collectedCount;
return { zan: getNumber(zan), cang: getNumber(cang), comment: getNumber(comment) };
});模拟人工操作
最后一种也是项目中经常会遇到的情况。比如我们需要用户登录了,网站提供了手机号登录和二维码登录两种方式。二维码需要我们将二维码展示在管理后台或者直接登录人工操作。手机号则可以配置一个自动化登录过程。
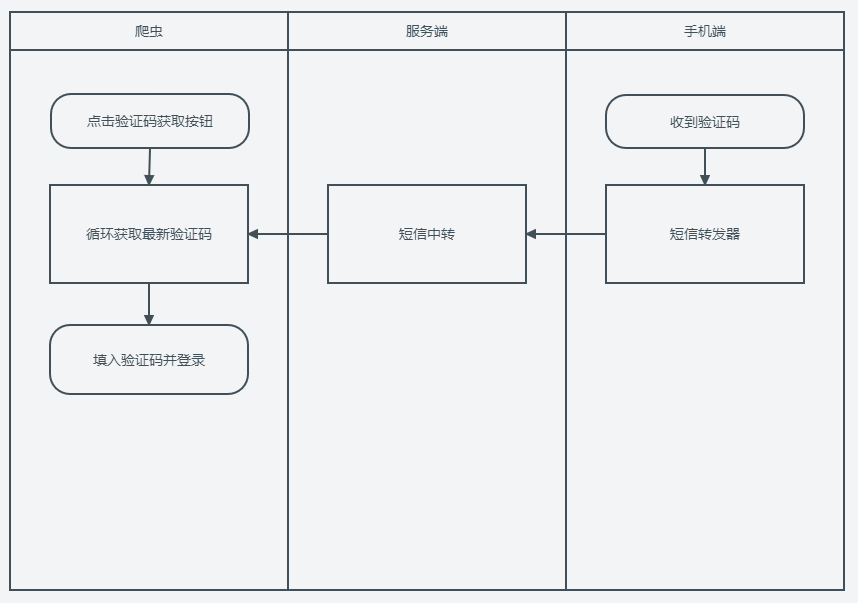
这个路径有时候可以简化为,遇到登录或者其他情况,暂停正在执行的爬虫操作,发通知到开发者。让开发者来手动处理。对于一个简单的爬虫项目来说,没必要搞的那么完备,有时候人工的介入更显得项目的难度。
需要注意的问题
阅读了上面部分的大部分人应该已经有一些了解,或者已经可以上手开发了。那么在开发中我们还需要了解一些非常开发的,或者是网站给爬虫开发者设置的难题。
异常情况处理
在数据抓取过程中,很多东西是网站开发者才知道的。我们只能在研究过程中不断遇到问题解决问题。
比如常见的有:
DOM不存在,需要我们判断之后再操作。
各种验证情况,比如弹出机器人判断、验证码判断登。
有时候会有闪退的情况,可能是浏览器内存满了或者代码逻辑bug等。
登录和账号问题
很多网站确实要求必须登录才能看到具体的数据。我们首先需要研究的是怎么判断当前状态是需要登录还是不需要登录。在每次数据抓取前,我们来检查一次,这样就可以在合十的时候暂停正在做的任务。
另一个问题就是登录多个人情况下怎么保证多个账号生效。简单的方式是记录Cookie或者LocalStorage的内容,每次切换用户的时候切换这2个的内容。第二种方式是切换浏览器的保存目录。比如playwright就可以直接设置用户目录,切换用户只需要切换目录即可。
代理问题
在多次多轮爬取之后,第一个遇到的问题其实就是反爬虫验证。常见的各种机器人验证,需要拼图、选字、选交通工具等。
我们需要考虑的第一种方式是放慢爬取节奏。比如原来是一分钟一次,现在变成5分钟一次等。这种可以缓解问题,部分项目可以解决问题。
第二种方式是使用代理,假装我们是全国各地不同地方的人在访问。大部分可以解决问题,但是也会有新的问题:代理不稳定、账号或者浏览器验证登。
浏览器指纹
有的网站对浏览器是有校验的,常见的方式是浏览器指纹,根据浏览器的特征产生对应的一个固定ID。从理论上来说97%的用户都可以区分开。
针对这种情况,我们需要设置几个浏览器特征,把这个特征和用户或者IP关联起来。这样就可以伪装自己是一个独立的浏览器设备。
乱码问题
有些网站看着是正常的,但是抓取到之后一看就是个乱码。这种网站其实使用的是一个特殊字体。他们把正常的字替换成了一种特殊的字体,用特殊字体库就可以看到内容。
针对这种情况,我们可用的办法其实很少。一般来说可以考虑在机器上单独部署一个OCR服务,利用OCR的能力来识别内容。另外一种方法就是找到他们的对应关系,直接反编译......哈哈。
有的单纯就是URL编码,需要DECode一下就行。
浏览器特征
上面几个库操作的浏览器其实是可以被识别到的。所有有些时候网站会直接根据浏览器特征返回空内容。针对这种情况,我们需要做的就是去掉浏览器特征即可。让浏览器变成一个正常的浏览器。
具体的代码我就不反了。可以去搜索一下xtract-stealth-evasions这个扩展的实现。
其他问题
还有一些是每个平台自己独特的问题要解决的。比如内部传小红书可以用过注入Cookie的方式绕过验证的弹出。具体的情况可以在具体的项目中去研究。
还需要什么功能
如果只是简单的抓一些数据,我们已经可以了。但是要达到自动化、24H运行,这些还是不行的。
针对一般的爬虫项目,我列出了一些爬虫项目应该有的功能。这些功能会在各个方面强化爬虫的能力。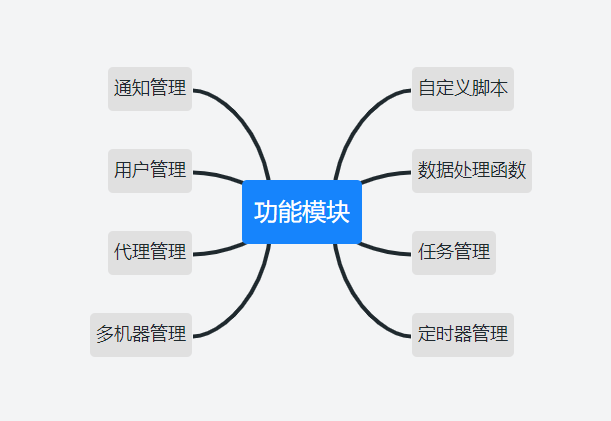
任务管理。用后台可视化的方式展示当前正在执行的任务。同时可以限制部分机器的并发,减少任务冲突的情况。
通知管理。最好是有一个通知,这样一旦出现任何异常,我们都可以知道。(随时准备介入处理异常)
代理管理。要想跑的多,大部分情况下还需要一个代理。
自定义脚本。通过自定义脚本的方式来扩展针对不同平台的抓取支持。
用户管理。通过界面的方式管理现在登录了哪些账号,哪些账号已经失效等。
多机器管理。一台机器能跑的任务是有限的,多台机器一起执行才是未来方向。
以上就是一个爬虫应该知道的基础知识。有了这些知识,开发一个爬虫已经是很简单的事情了。如果有人对完整的项目感兴趣,我可以写一个从0到1的系列。